
I am currently enrolled in a Master’s program for Electrical Science and Technology at the School of Electronic Information and Electrical Engineering (电子信息与电气工程学院), Shanghai Jiao Tong University (SJTU), Shanghai, China, and under the supervision of Professor Guanghui He.
My current research interests focus on Efficient ASIC Architecture Design for Emerging Applications.
- Efficient Hardware Accelerators for Autonomous Driving Systems
- Preprocessing: feature learning network (DAC 2023, TVLSI 2024)
- Backbone: 3D sparse convolution (ICCAD 2023)
- Multi-modality Fusion: vision-centric 3D perception (DAC 2024, TCAS-I 2025)
- Data Compression Techniques for High-bandwidth Requirement from Future Neural Networks (TCAS-II 2024)
- Efficient Hardware Accelerators for Neural Radiance Field (NeRF)
- Hardware/Software Co-Design for NERF based 3D reconstruction (TCAD 2025)
- Efficient Hardware Accelerators for Transformers
- KV Cache Compression (2 x DAC 2025)
- Bit-Serial Acceleration (DAC 2025)
- Processing-in-Memory (DAC 2025)
🔥 News
- 2025.04: 🎉🎉 One co-authored paper about Acceleration for Vision-Centric 3D Perception is accepted by TCAS-I.
- 2025.02: 🎉🎉 Our paper about DSA’s Efficiency Optimization on KV Cache in LLMs is accepted by DAC. One co-authored paper about Near Memory Processing for Generative LLM inference is accepted by DAC. One co-authored paper about Bit-serial Neural Network Acceleration is accepted by DAC.
- 2024.11: 🎉🎉 Our paper about Neural Rendering Acceleration is accepted by TCAD.
- 2024.03: 🎉🎉 The preprint version of our DAC’24 paper DEFA: Deformable Attention Accelerator is available on ArXiv.
- 2024.02: 🎉🎉 One co-authored paper about Deformable Attention Acceleration is accepted by DAC’24.
- 2024.02: 🎉🎉 One co-authored paper about NN data compression engine is accepted by IEEE TCAS-II.
- 2024.01: 🎉🎉 The extended paper of our DAC’23 is accepted by IEEE TVLSI.
- 2023.07: 🎉🎉 One co-authored paper about 3D Sparse Convolution Accelerator is accepted by ICCAD’23.
- 2023.02: 🎉🎉 One co-authored paper about Feature Learning Network Acceleration of Point Clouds is accepted by DAC’23.
📝 Publications
$^{\dagger}$: equal contribution.
Selected Publications
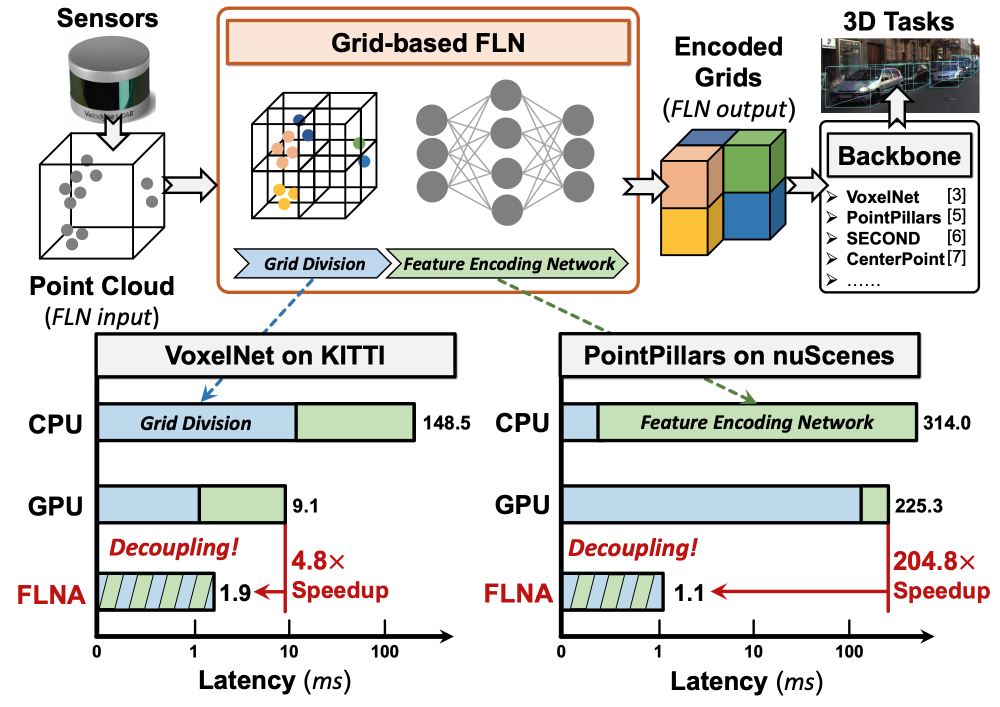
Dongxu Lyu$^{\dagger}$, Zhenyu Li$^{\dagger}$, Yuzhou Chen, Gang Wang, Weifeng He, Ningyi Xu and Guanghui He
- The first grid-based feature learning network accelerator with algorithm-architecture co-optimization for large-scale point clouds.
- It demonstrates substantial performance boost over the state-of-the-art point cloud accelerators while providing superior support of large-scale point clouds ($>10^6$ points in $\sim2$ ms).
- An extension of our DAC’24 paper.
- IEEE Transactions on Very Large Scale Integration (VLSI) Systems
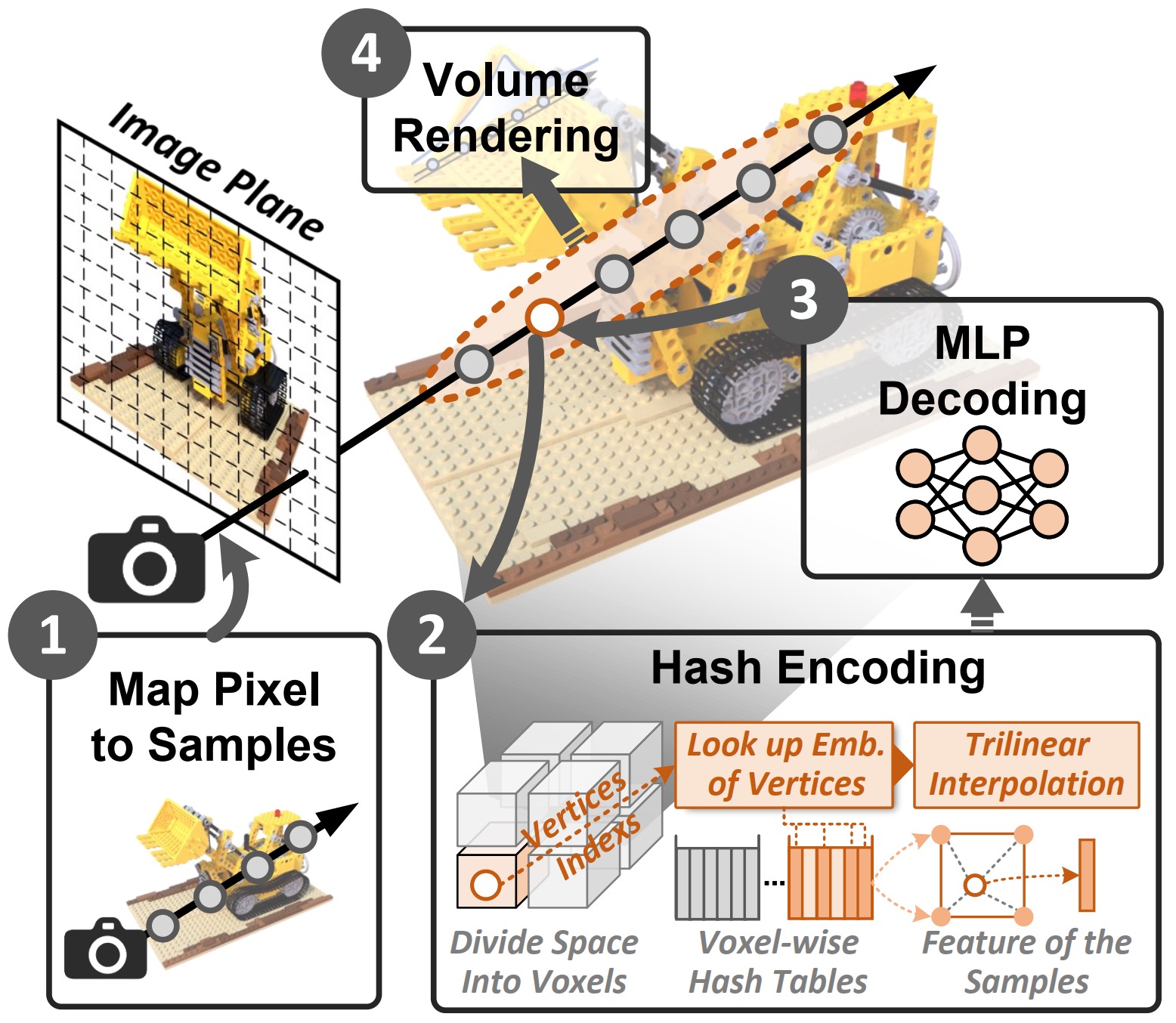
Neural Rendering Acceleration with Deferred Neural Decoding and Voxel-Centric Data Flow
Yuzhou Chen$^{\dagger}$, Zhenyu Li$^{\dagger}$, Dongxu Lyu, Yansong Xu and Guanghui He
- Proposed a deferred neural decoding method to aggregate the network queries, reducing the computation workload by $85.6\%$ compared to the original algorithm and only incurs $<0.5\%$ loss in rendering quality.
- Implemented a highly-pipelined accelerator utilizing voxel-centric dataflow, which achieves up to $2.9\times$ throughput, $36.5\times$ energy efficiency over the state-of-the-art related accelerators.
- IEEE Transactions on Computer-Aided Design of Integrated Circuits and Systems
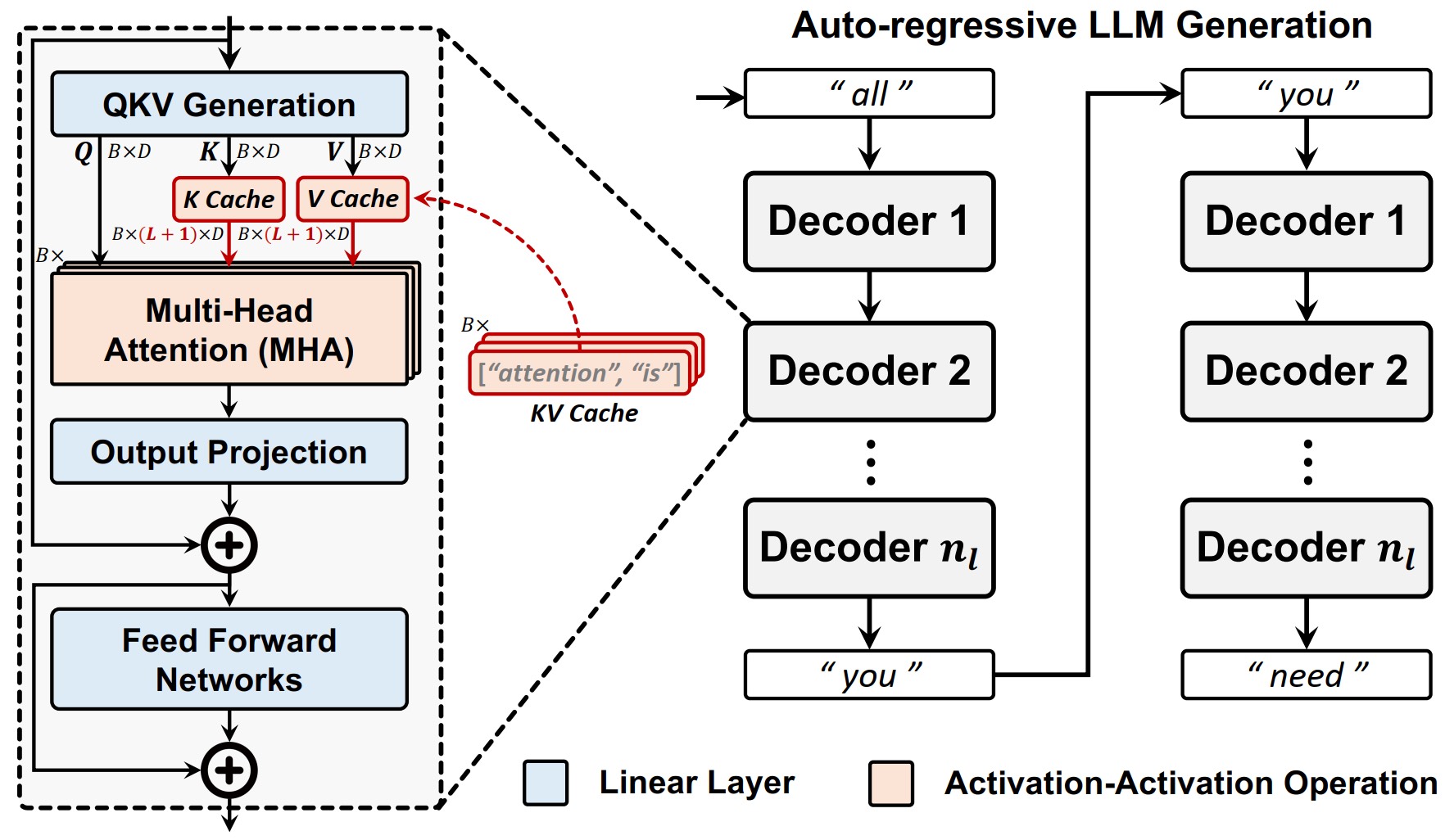
KVO-LLM: Boosting Long-Context Generation Throughput for Batched LLM Inference
Zhenyu Li$^{\dagger}$, Dongxu Lyu$^{\dagger}$, Gang Wang, Yuzhou Chen, Liyan Chen, Wenjie Li, Jianfei Jiang, Yanan Sun and Guanghui He
- Proposed a framework unifying quantization and pruning, which compresses KV cache by up to $92\%$.
- Implemented a multi-core architecture utilizing intra- and inter-core latency overlapping.
- 2025 62th ACM/IEEE Design Automation Conference (DAC)
Full Pub List
TCAS-I 2025An Efficient Multi-View Cross-Attention Accelerator for Vision-Centric 3D Perception in Autonomous Driving, Dongxu Lyu, Zhenyu Li, Yansong Xu, Gang Wang, Wenjie Li, Yuzhou Chen, Liyan Chen, Weifeng He and Guanghui He, in IEEE Transactions on Circuits and Systems I: Regular Papers, vol. 72, no. 7, pp. 3272-3285, July 2025.DAC 2025KVO-LLM: Boosting Long-Context Generation Throughput for Batched LLM Inference, Zhenyu Li$^{\dagger}$, Dongxu Lyu$^{\dagger}$, Gang Wang, Yuzhou Chen, Liyan Chen, Wenjie Li, Jianfei Jiang, Yanan Sun and Guanghui He, 2025 62th ACM/IEEE Design Automation Conference (DAC), San Francisco, CA, USA, 2025.DAC 2025VEDA: Efficient LLM Generation Through Voting-based KV Cache Eviction and Dataflow-flexible Accelerator, Zhican Wang, Hongxiang Fan, Haroon Waris, Gang Wang, Zhenyu Li, Jianfei Jiang, Yanan Sun and Guanghui He, 2025 62th ACM/IEEE Design Automation Conference (DAC), San Francisco, CA, USA, 2025.DAC 2025BitPattern: Enabling Efficient Bit-Serial Acceleration of Deep Neural Networks through Bit-Pattern Pruning, Gang Wang, Siqi Cai, Zhenyu Li, Wenjie Li, Dongxu Lyu, Yanan Sun, Jianfei Jiang and Guanghui He, 2025 62th ACM/IEEE Design Automation Conference (DAC), San Francisco, CA, USA, 2025.DAC 2025AttenPIM: Accelerating LLM Attention with Dual-mode GEMV in Processing-in-Memory, Liyan Chen$^{\dagger}$, Dongxu Lyu$^{\dagger}$, Zhenyu Li, Jianfei Jiang, Qin Wang, Zhigang Mao and Naifeng Jing, 2025 62th ACM/IEEE Design Automation Conference (DAC), San Francisco, CA, USA, 2025.TCAD 2024Neural Rendering Acceleration with Deferred Neural Decoding and Voxel-Centric Data Flow, Yuzhou Chen$^{\dagger}$, Zhenyu Li$^{\dagger}$, Dongxu Lyu, Yansong Xu and Guanghui He, in IEEE Transactions on Computer-Aided Design of Integrated Circuits and Systems, vol. 44, no. 7, pp. 2725-2737, July 2025.DAC 2024DEFA: Efficient Deformable Attention Acceleration via Pruning-Assisted Grid-Sampling and Multi-Scale Parallel Processing, Yansong Xu, Dongxu Lyu, Zhenyu Li, Yuzhou Chen, Zilong Wang, Gang Wang, Zhican Wang, Haomin Li and Guanghui He, 2024 61th ACM/IEEE Design Automation Conference (DAC), San Francisco, CA, USA, 2024.TCAS-II 2024A Broad-Spectrum and High-Throughput Compression Engine for Neural Network Processors, Yuzhou Chen, Jinming Zhang, Dongxu Lyu, Zhenyu Li and Guanghui He, in IEEE Transactions on Circuits and Systems II: Express Briefs, vol. 71, no. 7, pp. 3528-3532, July 2024.TVLSI 2024FLNA: Flexibly Accelerating Feature Learning Networks for Large-Scale Point Clouds with Efficient Dataflow Decoupling, Dongxu Lyu$^{\dagger}$, Zhenyu Li$^{\dagger}$, Yuzhou Chen, Gang Wang, Weifeng He, Ningyi Xu and Guanghui He, in IEEE Transactions on Very Large Scale Integration (VLSI) Systems, vol. 32, no. 4, pp. 739-751, April 2024.ICCAD 2023SpOctA: A 3D Sparse Convolution Accelerator with Octree-Encoding-Based Map Search and Inherent Sparsity-Aware Processing, Dongxu Lyu, Zhenyu Li, Yuzhou Chen, Jinming Zhang, Ningyi Xu and Guanghui He, 2023 IEEE/ACM International Conference on Computer Aided Design (ICCAD), San Francisco, CA, USA, 2023.DAC 2023FLNA: An Energy-Efficient Point Cloud Feature Learning Accelerator with Dataflow Decoupling, Dongxu Lyu, Zhenyu Li, Yuzhou Chen, Ningyi Xu and Guanghui He, 2023 60th ACM/IEEE Design Automation Conference (DAC), San Francisco, CA, USA, 2023.
💻 Projects
A High Performance Neural Processing Unit for Efficient CNN Inference (Oct. 2023 – Present)

Hybrid Precision Neural Network Processor for Edge Computing (Tape-out)
- High programmability and flexibility, designed for AI algorithms with multi-operator and multi-precision requirements.
- Equipped with an operator-assembly translation framework to support fast deployment of the entire network.
- Deployed in company’s intelligent perception terminals for real-time device status detection.
🎖 Honors and Awards
- 2025.09 National Scholarship for Graduate Student from Shanghai Jiao Tong University.
- 2025.09 1st Prize on China Postgraduate IC Innovation Competition (中国研究生创芯大赛) from Association of Chinese Graduate Education.
- 2024.11 Tang Youshuqi Scholarship from Shanghai Jiao Tong University.
- 2024.09 3rd Prize on China Postgraduate IC Innovation Competition (中国研究生创芯大赛) from Association of Chinese Graduate Education.
- 2023.06 Outstanding Graduate from Shanghai Jiao Tong University.
- 2023.06 Departmental Excellent Undergraduate Thesis (Department of Micro/Nano Electronics) from Shanghai Jiao Tong Unversity.
- 2021.11 The Outstanding Alumni Fund of the School of SEIEE from Shanghai Jiao Tong University.
- 2021.09 2nd Prize on Naitional Undergraduate Embedded Chip Design Competition (嵌入式芯片与系统设计竞赛) from Chinese Institute of Electronics.
📖 Educations

|
SHANGHAI JIAO TONG UNIVERSITYDegree: BachelorPeriod: 2019.09 - 2023.06 Major: Microelectronics Science and Engineering GPA: 4.03/4.3 (ranked 2nd out of 67) |
|
|
SHANGHAI JIAO TONG UNIVERSITYDegree: MasterPeriod: 2023.09 - 2026.03 (expected) Major: Integrated Circuit Science and Engineering GPA: 3.98/4.00 (ranked 1st out of 115) |
💻 Internships

|
Huixi Technology (辉羲智能)2022.11 - 2024.03Hardware & Toolchain Intern Shanghai, China. |